背景 虽然听过很多次,不过是第一次上手写字符串哈希。
做了一次牛客自闭场,第三题就是这个了,当时是没写出来…
这也是寒假最后一篇博文了,明天开学!
题目 Link: https://ac.nowcoder.com/acm/contest/9984/B
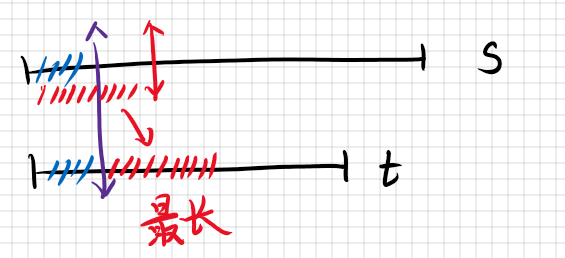
思路 形象一些,题目所求如图:
对于某一前缀(蓝色),只要求出$t$串中,除去该前缀最长的与$s$串某一前缀相同的部分即可,图中使用红色部分表示所求。
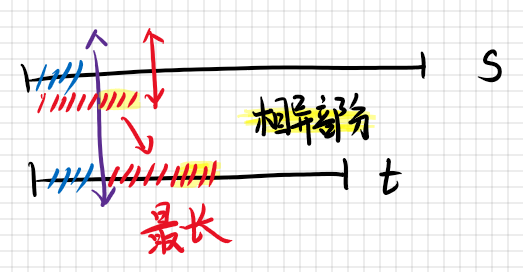
在刚开始做该题时,我尝试求两个前缀的差异部分,即:
但后来发现,求相异部分并不是个理想主意,因为相异部分与第一个前缀之间的部分,仍是需要比对的。由此,应该直接比对两个红色部分。
然后,我并没有往$Hash$的方向去想,而是在想$KMP$的最长公共前后缀能不能用到这道题上,不过在一段时间的尝试后还是失败了。
拜读题解,发现几种做法:
二分+字符串哈希
$exKMP$求解(非常类似的题目:传送门 )
后缀数组?新领域(雾)
这里主要看二分+字符串哈希的做法。
我们刚刚完成该题的一个瓶颈就是,不能快速的判断两个字符串是否相等,字符串哈希就是为了解决这个问题的。拜读OI-wiki ,字符串$Hash$有两种常用做法:
$hash[i] = hash[i - 1] p + s[i]$,此时$hash(s) = \sum _{i=1} ^{l} s[i] p^{l-i} \quad (Mod \ M)$
$hash[i] = hash[i-1] + s[i] p ^ {i-1}$,此时$hash(s) = \sum _{i=1} ^{l} s[i] p^{i-1} \quad (Mod \ M)$
两种做法都能做到一个前缀 的作用,可以通过类似前缀和的方法,做差得到$s[lf…rt]$的$Hash$值。
以第一种做法为例:
给出字符串acad
$hash[1] = a$
$hash[2] = a * p + c$
$hash[3] = a p ^ 2 + c p + a$
$hash[4] = a p ^ 3 + c p ^ 2 + a * p + d$
若要求$s[3…3]$的$Hash$值,只需要:$hash[3] - hash[3-1] * p ^ {3 - 3 + 1} \quad (Mod \ M)$,即得$a$。
推广到一般情况,有:
对于$p^{rt-lf+1}$的求解,可以使用快速幂,也可$O(n)$预处理,在本题中,使用快速幂需要卡常才能通过。
由于$hash$可能会产生冲突,可以使用双哈希,即是对一个字符串,使用两对不同的$p$和$M$求解,得到两个$hash$值,这样能够有效减少因$hash$冲突导致的错误。
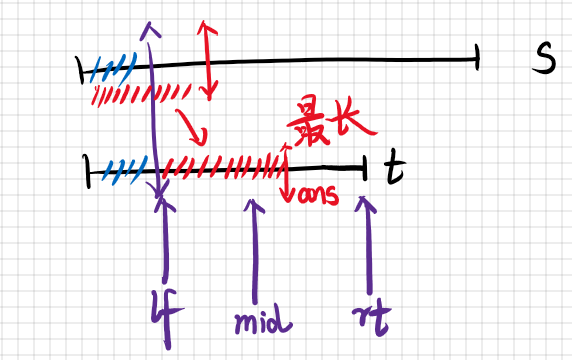
能够快速判断字符串是否相等之后,我们考虑如图二分寻找最长的相同前缀:
以此编写程序即可。
有一个点需要注意一下,在$hash[rt] - hash[lf-1] * p ^ {rt - lf + 1} \quad (Mod \ M)$计算的过程中,可能会由于取模的原因,出现负数。此时应将结果$res$进行操作变为正整数,即$((res \ mod \ M) + M) \ mod \ M$。此处之前遗漏了,只过了六个点。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <bits/stdc++.h> #define int long long const int maxn = 1e5 + 5 ;using namespace std ;const int p1 = 233 , mod1 = 998244353 ;const int p2 = 131 , mod2 = 1e9 + 7 ;struct strhash { int hash1; int hash2; }h1[maxn], h2[maxn]; int len1, len2, pow1[maxn], pow2[maxn];char s[maxn], t[maxn];inline int qpow (int a, int b, int p) if (b == 0 ) return 1 ; int tmp = qpow(a, b / 2 , p); tmp = (tmp * tmp) % p; if (b & 1 ) tmp = (tmp * a) % p; return tmp; } inline bool check (int lf, int rt) int len = rt - lf + 1 ; if (len > len1) return false ; int sh1 = h1[len - 1 ].hash1, sh2 = h1[len - 1 ].hash2; int th1 = (((h2[rt].hash1 - (h2[lf - 1 ].hash1 * pow1[rt - lf + 1 ])) % mod1) + mod1) % mod1; int th2 = (((h2[rt].hash2 - (h2[lf - 1 ].hash2 * pow2[rt - lf + 1 ])) % mod2) + mod2) % mod2; return sh1 == th1 && sh2 == th2; } signed main (void ) scanf ("%s" , s); scanf ("%s" , t); len1 = strlen (s), len2 = strlen (t); h1[0 ].hash1 = h1[0 ].hash2 = s[0 ]; h2[0 ].hash1 = h2[0 ].hash2 = t[0 ]; for (int i = 1 ; i <= len1 - 1 ; i++) h1[i].hash1 = (h1[i - 1 ].hash1 * p1 + s[i]) % mod1, h1[i].hash2 = (h1[i - 1 ].hash2 * p2 + s[i]) % mod2; for (int i = 1 ; i <= len2 - 1 ; i++) h2[i].hash1 = (h2[i - 1 ].hash1 * p1 + t[i]) % mod1, h2[i].hash2 = (h2[i - 1 ].hash2 * p2 + t[i]) % mod2; pow1[0 ] = pow2[0 ] = 1 ; for (int i = 1 ; i <= maxn - 5 ; i++) pow1[i] = (pow1[i - 1 ] * p1) % mod1, pow2[i] = (pow2[i - 1 ] * p2) % mod2; int ans = 0 ; for (int i = 1 ; i <= len1; i++) { if (h1[i - 1 ].hash1 == h2[i - 1 ].hash1 && h1[i - 1 ].hash2 == h2[i - 1 ].hash2) { int lf = i, rt = len2 - 1 , nans = -1 ; while (lf <= rt) { int mid = (lf + rt) / 2 ; check(i, mid) ? nans = mid, lf = mid + 1 : rt = mid - 1 ; } if (nans != -1 ) ans += nans - i + 1 ; } } printf ("%lld\n" , ans); return 0 ; }
别的 手写玩了一下双哈希,其实还是很好写的,不过也得能够想到该这么解决才行。有一些算法确实见的少了…
明天就要开学了,回过头来,看一下自己整个寒假,做的题,学的知识,还是太少太少了…
只有$66$题,主要集中在蓝桥杯和牛客比赛,$Codeforces$和$AtCoder$都鸽鸽了…
这样颓你怎么能脱离打铁匠的称号呢?
除了$ACM$,项目也没有说写了啥啊…
嗯,倒是有想法写个在线查重系统,主要是方便自己,配个$sim$上去就行…
想顺便趁写这个系统学一下$Golang$,据说很好用?
其实写$Web$就不只学$Golang$了…$html,js,css$这三样以前都是有所接触但都不深U•ェ•*U
必须大概看一下才能搞这东西…
不过如果只实现功能不写太漂亮前端啥的我那点零碎知识可能也够用?